CPU服务器部署大模型详细教程,企业可在1小时内基于元脑CPU推理服务器NF8260G7和NF8480G7快速部署并运行DeepSeek-R1和Qwen3、QwQ等大模型。CPU服务器部署大模型的软硬协同优化方案,首次投入可节约80%以上建设成本,且运行功耗更低,运维更便捷,有效降低客户TCO,为企业提供了一种更经济高效的算力选择。

〓 CPU运行大模型推理的需求:面临框架、环境等多重考验
大模型推理技术快速发展,实现CPU轻量化模型推理是业界创新方案,但一般企业要在CPU服务器实现大模型部署,往往面临诸多难题:
缺少适配框架:模型部署需要推理框架支持,推理框架对CPU架构优化有限,存在计算资源利用率低、并行策略低效等问题,难以释放CPU全量计算潜力;
计算环境复杂:需精准匹配指令集加速库(如AMX/AVX-512)、内存管理工具及量化依赖包,环境配置容错率低高;
无部署流程指导:缺失针对CPU拓扑结构的部署最佳实践,包括CPU内存绑定、线程分配等关键参数调优指南,导致部署效率低下。
浪潮信息针对CPU推理服务器的大模型部署场景进行了全方位优化,包括硬件架构设计、软件调优和量化算法创新,并基于实践经验总结出包含环境配置、模型部署和应用接入和性能调优等关键环节的高效四步部署指南,企业可在1小时内完成DeepSeek-R1 32B、QwQ-32B私有化部署,实现高性能、低成本的大模型落地。实测数据显示,该方案基于元脑CPU推理服务器NF8260G7和NF8480G7部署大模型,支持单用户超过20 tokens/s的推理性能,并能同时处理20个并发用户请求,实现高性能、低成本的大模型落地。

〓 CPU服务器本地快速部署DeepSeekR1-32B大模型指南
■ 第一步 推理框架选择
在大模型私有部署的企业级应用场景中,推理框架的选择尤为关键。当前,vLLM和SGLang凭借卓越的性能、强大的并发处理能力和良好的可扩展性,已成为业界广泛认可的企业级开源首选方案。
针对企业级CPU推理的应用需求,元脑服务器选择vLLM推理框架,不仅拥有卓越的推理性能,还支持更丰富的模型推理数值精度,除常见的FP16和BF16之外,还兼容AWQ、GPTQ等多种4bit和8bit主流量化算法,灵活适配不同规模和精度要求的模型,在保证推理效率的同时,有效降低部署所需的硬件资源。
■ 第二步 服务器环境准备
为精准匹配指令集加速库(如AMX/AVX-512)、内存管理工具及量化环境,在推理服务部署前,需要安装服务器操作系统、Docker驱动等基础软件,并将CPU状态提前进行设置,以获取器更好的推理计算性能。
■ 第三步 推理服务部署
针对大多数用户,可以通过开源社区的OpenStation平台在CPU服务器部署大模型,操作简便,内置性能优化方案,省时省力;而对于有定制化、安全或性能有特殊需求的用户,也可选择Docker手动部署。
//基于OpenStation自动化部署
● 一站式大模型推理服务部署和管理平台,兼容标准 OpenAI API 接口,内置vLLM推理引擎
● 首先在“模型库”中选择需要的DeepSeek模型进行下载
● 进入“模型服务”,点击“新增部署”,按照引导选择模型来源和部署节点,CPU节点平台会自动推荐vLLM(CPU-only)作为推理引擎
● 提交部署,部署完成后可在“模型服务”页面查看
//基于Docker手动部署
● 把定制优化的vLLM打包成Docker镜像,存储于阿里云easyds Docker镜像仓库
● 部署32B模型时,建议使用AWQ 4bit量化版本,模型权重从Huggingface或modelscope上下载
● 使用vLLM镜像创建容器,并把模型权重所在的路径挂载到容器中
● 容器启动后,在容器中启动vllm服务
■ 第四步 应用接入
//基于本地客户端接入
基于OpenChat、ChatBox或CherryStudio等UI客户端,用户可以方便地访问在服务器上部署的DeepSeek 服务,并可以基于个人文档构建知识库和实现联网搜索等功能。

//基于浏览器接入大模型
元脑CPU推理服务器支持在部署 vllm 推理服务的同时,同步集成 Open WebUI 。Open WebUI(https://openwebui.com/)是一款开源且可自托管的Web用户界面工具,专为本地或私有部署的大语言模型交互而设计。用户无需在本地安装客户端,即可通过Web界面便捷访问和使用大模型服务。
OpenStation已全面集成了Open WebUI,支持一键部署,并实现用户账号与模型服务的统一管理。平台功能涵盖系统配置、服务监控、模型管理和权限控制等方面。
基于该部署指南,元脑CPU推理服务器NF8260G7和NF8480G7单台服务器即可高效运行DeepSeek-R1和Qwen3、QwQ等模型,实现单用户超过20 tokens/s的推理性能,并能同时处理20个并发用户请求,为更多互联网、金融、医疗行业用户,带来高效、稳定的DeepSeek等大模型部署方案,助力大模型快速落地应用。
服务专线:028-85041134 18380340549
公司地址:成都市武侯区一环路南二段2号新世纪商业中心东楼17B
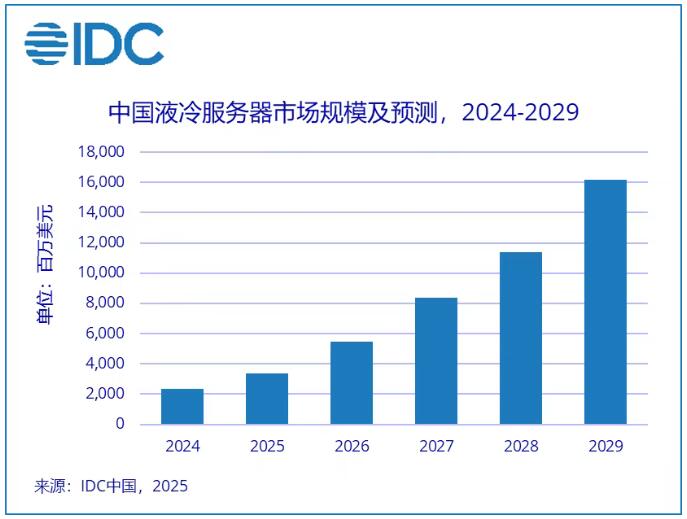
【成都浪潮服务器总代理】在全球数字化与智能化飞速发展的当下,液冷技术正成为各行各业关注的焦点,在全球范围内的渗透率稳步提升。中国液冷市场也展现出强劲的增长势能和巨大发展前景,IDC预计,2024-2029年中国液冷服务器市场年复合增长率将达到46.8%,2029年市场规模将达到162亿美元。


【成都浪潮服务器代理商】浪潮NF5468G7是浪潮信息畅销海内外NF5468系列的最新产品,是具备卓越多元算力性能、极致弹性架构扩展的全新一代人工智能服务器,4U空间内部署8颗最高性能GPU,可根据应用场景实现拓扑切换。搭载2颗Intel第四代/第五代至强可扩展处理器,提供多达112个处理器核心、8TB系统内存和300TB本地高速存储,面向深度学习、元宇宙、AIGC、AI+Science等复杂应用场景,打造智算时代最强适应性多元算力平台。

标准由浪潮信息与多家企业、高校和研究所共同编制,是首个面向车间级的数字孪生架构标准,将于2026年1月1日起实施。此标准为广大企业规划、建设和使用车间数字孪生提供规范性参考,以加快智能制造应用实践,提升建设效率。

【成都浪潮服务器总代理】浪潮NF5270G7机架式服务器面向中等规模企业客户市场推出的双路机架式服务器,实现性能、扩展性与经济性的均衡设计,满足业务对于计算性能、存储性能、网络带宽要求的前提下,具有非常优异的性价比,特别适合大数据、CDN、虚拟化、非关系型数据库、视频编解码等场景。

浪潮NP3020M7是新一代入门级单路塔式服务器,专为远程办公环境、邮件以及打印服务等整体解决方案提供可靠的硬件基础。可根据客户实际应用环境,灵活扩展,满足客户不断变更的应用需求,应对不断变更的运行环境。

浪潮NP5570M5是全新一代中高端双路塔式服务器产品,具备出色性能、灵活扩展、稳定可靠等特性。

提供丰富的存储矩阵,最大程度满足扩展性及网络均衡性需求,同时在1U机型首次导入风冷、冷板液冷、浸没液冷多维散热方案,满足更多高密数据中心低PUE诉求。

2U双路存储优化服务器,采用创新三层存储架构,在高存储密度、超强算力、高网络带宽、智能管理等方面得到大幅提高,适用于大数据、CDN、超融合、分布式存储等业务场景。

浪潮NF5280M7支持英特尔®至强®第四代/第五代可扩展处理器,在计算性能、存储性能及可扩展性方面均实现极致设计;支持前、后IO维护等多元部署方式,打破传统数据中心运维瓶颈;融合诸多业界先进技术,导入液冷、EVAC等高效散热模式;同时秉承开放创新、极致精益、绿色节能、智能高效的四大设计理念,以百变形态面对各行各业多样化场景需求。

4U双路存储优化服务器,兼顾高存储容量、强大计算性能和极致IO扩展能力,非常适用于温/冷数据存储、视频存储、大数据 存储、云存储池搭建等应用场景。

是一款高端四路机架式服务器。产品以强劲的计算性能,模块化的灵活设计,卓越的扩展性,更优的可靠性和安全特性,为客户数据密集型关键业务而优化

1U空间实现性能、密度、扩展性最大化设计,适用于高性能计算,虚拟化等多种计算密集型应用场景,满足高密数据中心部署。

浪潮NF5266M6是一款高密度机架式存储服务器。

浪潮NF5270M6是一款中端2U服务器,以精简设计理念为小型虚拟化、数据库、办公OA系统等应用场景量身定做的服务器。

浪潮NF5280M6是搭载第三代英特尔®至强®可扩展处理器的一款双路旗舰通用机架式双路服务器,保持了一贯的高品质、高可靠的表现,以强劲的计算性能,完善的生态兼容,灵活百变的配置变换满足各行业应用配置需求。

NF8260M6 是为针对CSP企业客户等需求,基于全新一代英特尔®至强®可扩展处理器设计的一款2U4路机架式服务器。在有限的空间内保证更高计算密度的同时,为企业级客户提供降低云计算数据中心TCO的解决方案。

NF8480M6是搭载第三代英特尔®至强®可扩展处理器的一款高端四路机架式服务器。该产品以强劲的计算性能,模块化的灵活设计,卓越的扩展性,更优的可靠性和安全特性,为客户数据密集型关键业务而优化,适用于大型交易数据库、内存数据库、虚拟化整合、高性能计算、深度学习以及ERP等应用场景。

搭配高效算力及极致扩展实现整机性能最佳平衡,满足轻量化负载需求,适配云计算、虚拟化等主流计算场景,同时满足高密数据中心部署。

该产品具备多核心、高主频、大缓存、高扩展性的特性,使单处理器性能得到最大发挥,2U空间实现存储、扩展最大化设计
