随着生成式AI步入大规模部署阶段,智算系统的硬件故障已成为难以避免的“灰犀牛”,比频繁宕机更制约效率的是难以定位故障根因,系统宕机瞬间操作系统与底层硬件之间信息中断导致关键日志缺失,运维被迫陷入“盲换硬件”的被动局面。
针对这一结构性难题,元脑服务器操作系统KOS(简称元脑KOS)创新推出“GPU黑匣子”功能,通过建立跨平台协同机制,在系统崩溃瞬间让OS内核与BMC紧急通信,实现GPU故障根因的精准定位与现场保全,让大规模系统的故障定位时间从小时级压缩至分钟级。

大规模智算系统故障频发 根因难觅成影响效率瓶颈
当前,在大模型训练与推理的实际应用中,硬件故障已成为影响系统稳定性的关键挑战。以业内某典型的大规模训练任务为例:由1.6万张旗舰级显卡组成的集群,在历时54天训练一个4050亿参数的模型过程中,共发生419次意外中断,平均每3小时出现一次故障。其中,超过58%的中断由GPU相关硬件问题引发,而“根因不清”则是导致故障反复出现、难以根治的主要原因。 GPU故障定位困难,主要源于两方面:
一是服务器架构复杂化与链路“黑盒化”。随着AI服务器集成度不断提升,模块化维护设计不足,加之GPU链路层缺乏有效的监测手段与诊断标准,导致故障部件难以被精准定位;
二是系统性分析能力缺失。面对难以复现的应用类故障,缺乏顶层、系统的根因分析方法论,过度依赖复现测试与上游FA(现场应用)支持,导致问题闭环周期被显著拉长。
在技术层面,实现GPU故障的快速精准定位,需要基于开放架构,在宕机发生的瞬间,将GPU状态有效存储下来。然而,现有监控手段存在明显能力缺口:OS能够快速响应并生成Panic瞬间及之前的系统日志,但在系统崩溃等极端场景下,日志往往来不及落盘;BMC虽不受系统崩溃影响,但其通常仅以秒级轮询GPU传感器,采样频率有限,并只能获取温度、功耗等基础指标,无法深入GPU内部捕获实时、细粒度的微观运行状态。
因此,如何弥合这一能力缺口,实现故障时刻的精准信息捕获,已成为提升大规模系统运行效率的关键命题。
元脑KOS推出“GPU黑匣子” 紧急时刻打通OS内核与BMC通信通道
为了解决上述难题,元脑KOS基于元脑服务器进行GPU故障转储创新实践,推出“GPU黑匣子”功能。在操作系统与硬件之间建立跨平台协同机制,充分利用OS洞察力与BMC持久性——在系统崩溃的“临界时刻”,操作系统内核黑匣子模块通过宕机信号捕获、毫秒级系统信息及日志快照、非中断通信请求等技术,迅速建立OS内核与BMC之间的通信通道、快速收集系统崩溃时日志信息、触发GPU故障信息采集,确保GPU底层状态信息得以完整保全。

GPU黑匣子跨平台协同机制的可靠性,依赖于KOS内核与BMC固件的多项底层技术支撑。
在OS侧,通过内核panic_notifier机制实时捕获系统宕机信号,并立即触发Reset事件阻塞机制以暂停操作系统复位,防止现场数据丢失;在此期间,快速收集dmesg日志、PCIe设备列表、module信息、MCE信息及系统版本等数据,同时向BMC发送故障抓取通知。上述Reset事件阻塞机制为BMC预留了足够的时间窗口,确保其完成MB量级底层数据的采集。
在BMC侧,该机制依托OpenBMC架构中的特定组件实现:BMC实时监测组件接收到KOS发送的故障抓取通知,开始转储KOS收集的故障日志,同时通过D-Bus(数据总线)通知到gpu-debug-collector组件,该组件遍历所有GPU节点并执行dumplog函数,进一步采集GPU故障日志。
KOS与BMC采集到所有故障日志统一封装为CPER标准格式,可直接导入主流运维平台,帮助运维团队实现故障根因的快速定位。
全面采集GPU故障信息,基于微观证据实现故障精准定位
与传统监测方案仅能获取温度、功耗等表层信息不同,GPU黑匣子实现了从芯片核心到系统互连的全栈深度采集。
GPU层面:系统捕获系统崩溃时完整的GPU内部日志数据及状态信息,包括ECC单比特/双比特错误计数、SRAM纠错记录及计算核心挂起状态,用于区分显存物理损坏与逻辑电路异常,以及运算核及内部总线状态等信息判定崩溃时GPU内部计算部件监控状态;
单机互连层面:记录PCIe TLP错误、AER(Advanced Error Reporting)日志及显卡掉线前后的协议栈状态,定位PCIe链路不稳定或主板走线干扰;
多机通信层面:采集互连链路CRC错误码、链路重训练次数及互连交换设备端口统计数据,诊断分布式训练中的网络拓扑异常。这种立体化的数据捕获能力,使得运维人员能够依据崩溃瞬间的微观证据链,精准判定故障根因所在的具体技术层级。
以某大规模系统在迭代多模态大模型期间故障为例,每周两次宕机导致长达12小时的任务回滚,在业务连续性压力下,运维团队连续更换了三张GPU,但故障却依旧发生。引入“GPU黑匣子”特性后,宕机发生的瞬间,KOS冻结CPU Reset动作,触发双域数据并发抓取:OS层实时捕获PCIe AER日志,BMC同步抓取GPU内部功耗计数器与总线状态。通过日志快照,最终了解到故障原因是PCIe链路发生连续硬件级重传并触发Fatal Error,运维团队由此锁定根因是主板电源模块老化而非GPU本身,针对性更换服务器电源后实现故障根治。
“GPU黑匣子”凭借微观证据链的故障精准定位,重塑了以往产业链上下游协同和创新模式。
对于终端客户与云运营商,GPU的故障精准定位,不仅可以缩短平均修复时间(MTTR),显著提升算力利用率(MFU),更让运维能基于历史数据构建预测模型,实现从盲目抢修向预防性维护的跨越。
对于GPU厂商与服务器OEM厂商,这种透明的故障追溯机制将加速GPU的产品成熟迭代,方便研发人员高效修复产品缺陷。更重要的是,准确的根因分析有效扼制了因“盲目换卡”导致的无缺陷退货(NTF)问题,在降低售后成本的同时,推动了跨厂商间的产品质量联合治理与供应链协同。
浪潮元脑AI算力方案供应商 —— 成都强川科技有限公司
服务专线:028-85041134 18380340549
公司地址:成都市武侯区一环路南二段2号新世纪商业中心东楼17B
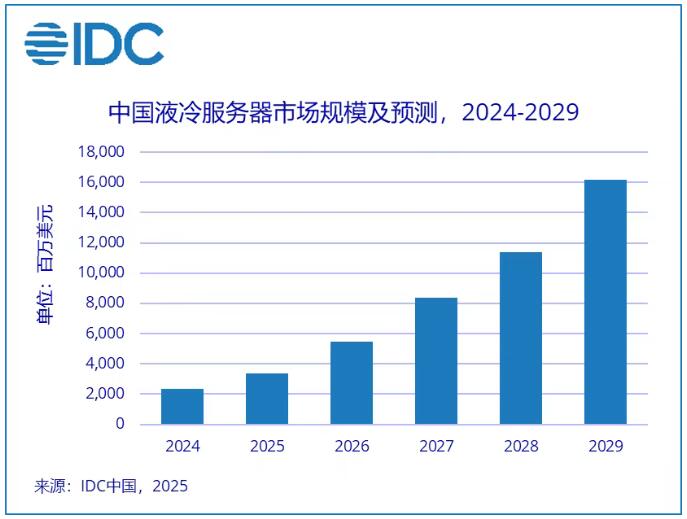
【成都浪潮服务器总代理】在全球数字化与智能化飞速发展的当下,液冷技术正成为各行各业关注的焦点,在全球范围内的渗透率稳步提升。中国液冷市场也展现出强劲的增长势能和巨大发展前景,IDC预计,2024-2029年中国液冷服务器市场年复合增长率将达到46.8%,2029年市场规模将达到162亿美元。


【成都浪潮服务器代理商】浪潮NF5468G7是浪潮信息畅销海内外NF5468系列的最新产品,是具备卓越多元算力性能、极致弹性架构扩展的全新一代人工智能服务器,4U空间内部署8颗最高性能GPU,可根据应用场景实现拓扑切换。搭载2颗Intel第四代/第五代至强可扩展处理器,提供多达112个处理器核心、8TB系统内存和300TB本地高速存储,面向深度学习、元宇宙、AIGC、AI+Science等复杂应用场景,打造智算时代最强适应性多元算力平台。

标准由浪潮信息与多家企业、高校和研究所共同编制,是首个面向车间级的数字孪生架构标准,将于2026年1月1日起实施。此标准为广大企业规划、建设和使用车间数字孪生提供规范性参考,以加快智能制造应用实践,提升建设效率。

【成都浪潮服务器总代理】浪潮NF5270G7机架式服务器面向中等规模企业客户市场推出的双路机架式服务器,实现性能、扩展性与经济性的均衡设计,满足业务对于计算性能、存储性能、网络带宽要求的前提下,具有非常优异的性价比,特别适合大数据、CDN、虚拟化、非关系型数据库、视频编解码等场景。

浪潮NP3020M7是新一代入门级单路塔式服务器,专为远程办公环境、邮件以及打印服务等整体解决方案提供可靠的硬件基础。可根据客户实际应用环境,灵活扩展,满足客户不断变更的应用需求,应对不断变更的运行环境。

浪潮NP5570M5是全新一代中高端双路塔式服务器产品,具备出色性能、灵活扩展、稳定可靠等特性。

提供丰富的存储矩阵,最大程度满足扩展性及网络均衡性需求,同时在1U机型首次导入风冷、冷板液冷、浸没液冷多维散热方案,满足更多高密数据中心低PUE诉求。

2U双路存储优化服务器,采用创新三层存储架构,在高存储密度、超强算力、高网络带宽、智能管理等方面得到大幅提高,适用于大数据、CDN、超融合、分布式存储等业务场景。

浪潮NF5280M7支持英特尔®至强®第四代/第五代可扩展处理器,在计算性能、存储性能及可扩展性方面均实现极致设计;支持前、后IO维护等多元部署方式,打破传统数据中心运维瓶颈;融合诸多业界先进技术,导入液冷、EVAC等高效散热模式;同时秉承开放创新、极致精益、绿色节能、智能高效的四大设计理念,以百变形态面对各行各业多样化场景需求。

4U双路存储优化服务器,兼顾高存储容量、强大计算性能和极致IO扩展能力,非常适用于温/冷数据存储、视频存储、大数据 存储、云存储池搭建等应用场景。

是一款高端四路机架式服务器。产品以强劲的计算性能,模块化的灵活设计,卓越的扩展性,更优的可靠性和安全特性,为客户数据密集型关键业务而优化

1U空间实现性能、密度、扩展性最大化设计,适用于高性能计算,虚拟化等多种计算密集型应用场景,满足高密数据中心部署。

浪潮NF5266M6是一款高密度机架式存储服务器。

浪潮NF5270M6是一款中端2U服务器,以精简设计理念为小型虚拟化、数据库、办公OA系统等应用场景量身定做的服务器。

浪潮NF5280M6是搭载第三代英特尔®至强®可扩展处理器的一款双路旗舰通用机架式双路服务器,保持了一贯的高品质、高可靠的表现,以强劲的计算性能,完善的生态兼容,灵活百变的配置变换满足各行业应用配置需求。

NF8260M6 是为针对CSP企业客户等需求,基于全新一代英特尔®至强®可扩展处理器设计的一款2U4路机架式服务器。在有限的空间内保证更高计算密度的同时,为企业级客户提供降低云计算数据中心TCO的解决方案。

NF8480M6是搭载第三代英特尔®至强®可扩展处理器的一款高端四路机架式服务器。该产品以强劲的计算性能,模块化的灵活设计,卓越的扩展性,更优的可靠性和安全特性,为客户数据密集型关键业务而优化,适用于大型交易数据库、内存数据库、虚拟化整合、高性能计算、深度学习以及ERP等应用场景。

搭配高效算力及极致扩展实现整机性能最佳平衡,满足轻量化负载需求,适配云计算、虚拟化等主流计算场景,同时满足高密数据中心部署。

该产品具备多核心、高主频、大缓存、高扩展性的特性,使单处理器性能得到最大发挥,2U空间实现存储、扩展最大化设计
